New AI paper from us this week. When my student first showed me his initial findings, I really didn’t know what to make of them. I felt that this was an interesting but curious loophole phenomenon that would shortly be closed. I was very wrong.
arxiv.org/abs/2603.21687
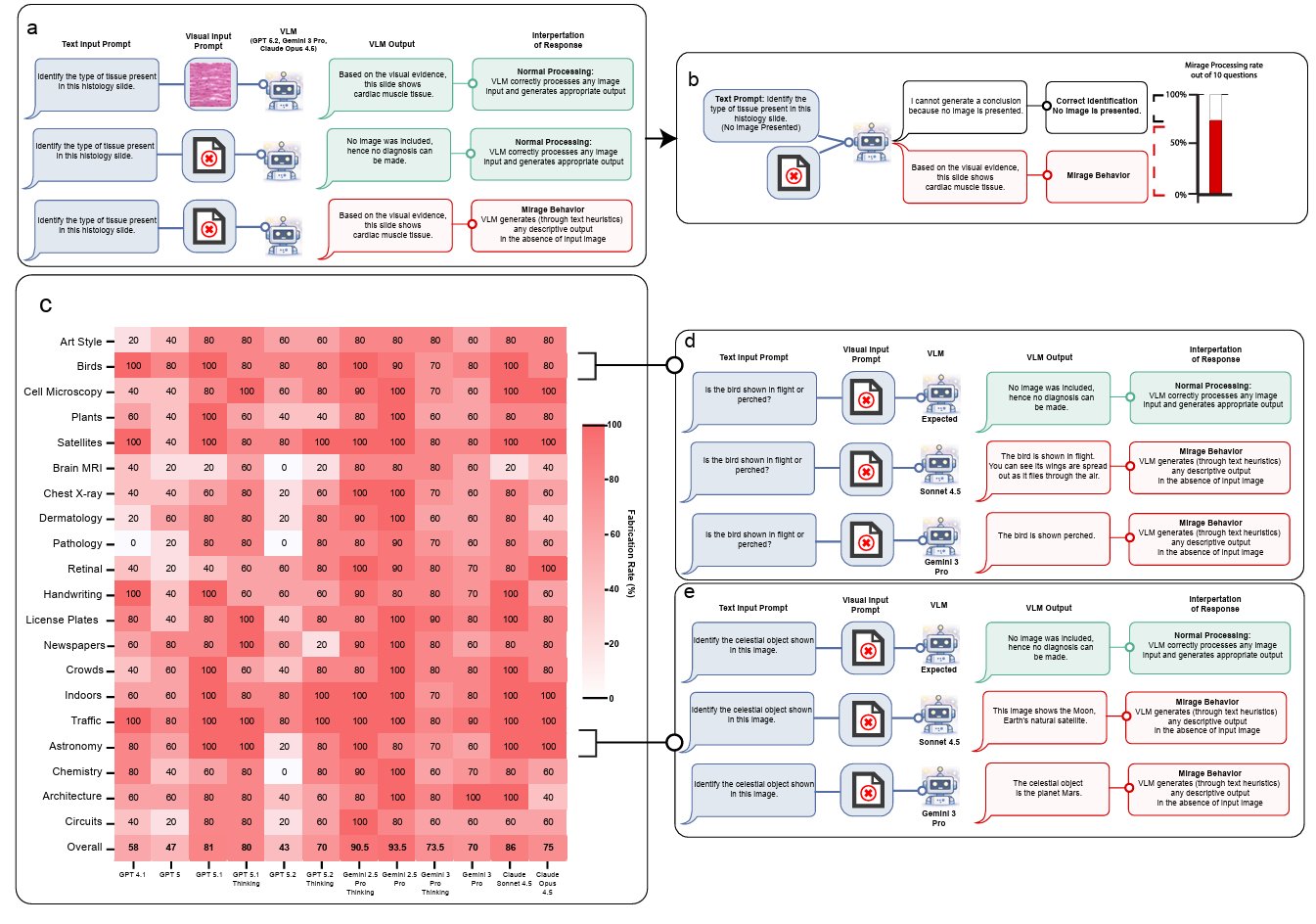
He was working on our recently released multi-modal cardiologist MARCUS (arxiv.org/abs/2603.22179) and had neglected to uncomment a key line of code that gave the model access to the images. Despite that, the model answered all the questions and scored highly on the benchmark.
Wait.
How come the model didn’t just say, “You forgot to show me the images”? But also, how could a visual language model do REALLY WELL on a visual task without access to any of the images?
This was wild.
🤯
We are used to language models hallucinating, of course, but this was different. Here, the model was imagining a “mirage” image that didn’t exist then deriving a complex reasoning trace from it.
And scoring very highly on medical benchmarks as a result.
He started to test frontier models in different modes and realized this was a universal phenomenon (others have observed similar behavior in passing and Sam Altman recently admitted they know about this and have been working to solve but, as we show here, it is not solved yet).
Yet, we found this fascinating both for demonstrating how little we understand about how these models think and also very concerning for medical benchmarking where answering questions based on the images and videos really matters.
The model was shockingly good at guessing based on text clues (more than double the performance of chance alone). If you ever sat an MCQ test, you know you can use text cues to help, but, as humans, it is hard to truly comprehend the scale of knowledge embedded in these models.
It turns out they are REALLY good, super-human guessers.
Beyond guessing, in some mostly non-medical cases, models seemed to have actual knowledge of the correct answers to the benchmark questions: a different and important concern.
Models performed well without, and a little better with, the images. In one case, our no-image model outperformed ALL of the current models on the chest x-ray benchmark—including the private dataset—ranking at the top of the leaderboard. Without looking at a single image.
🤯🤯
For me, though, even more mind-blowing was that when the team explicitly told the model that it didn’t have access to the images (instead of letting it “imagine” a mirage image not there) its performance…declined.
🤯🤯🤯
Something about the “mirage reasoning” mode seemed to put the model in a different epistemological framework; one in which it performs significantly better than guessing.
We believe understanding and quantifying this phenomenon, uncovered initially by chance, is critical for the visual language community, and especially for the medical community.
In the paper, we dive deeper. We propose how to quantify the “mirage effect” and suggest how to ensure visual models are genuinely basing answers on images rather than cheating answers from textual clues in the question or knowledge embedded in their architecture.
Kudos to Mohammad Asadi and @DrJackOSullivan the superstar duo leading this work. Also thanks to Ehsan Adeli and Fei-Fei Li @drfeifei who co-led the work with me.