Introducing OpenMythos
An open-source, first-principles theoretical reconstruction of Claude Mythos, implemented in PyTorch.
The architecture instantiates a looped transformer with a Mixture-of-Experts (MoE) routing mechanism, enabling iterative depth via weight sharing and conditional computation across experts.
My implementation explores the hypothesis that recursive application of a fixed parameterized block, coupled with sparse expert activation, can yield improved efficiency–performance tradeoffs and emergent multi-step reasoning.
Learn more ⬇️🧵
2 /
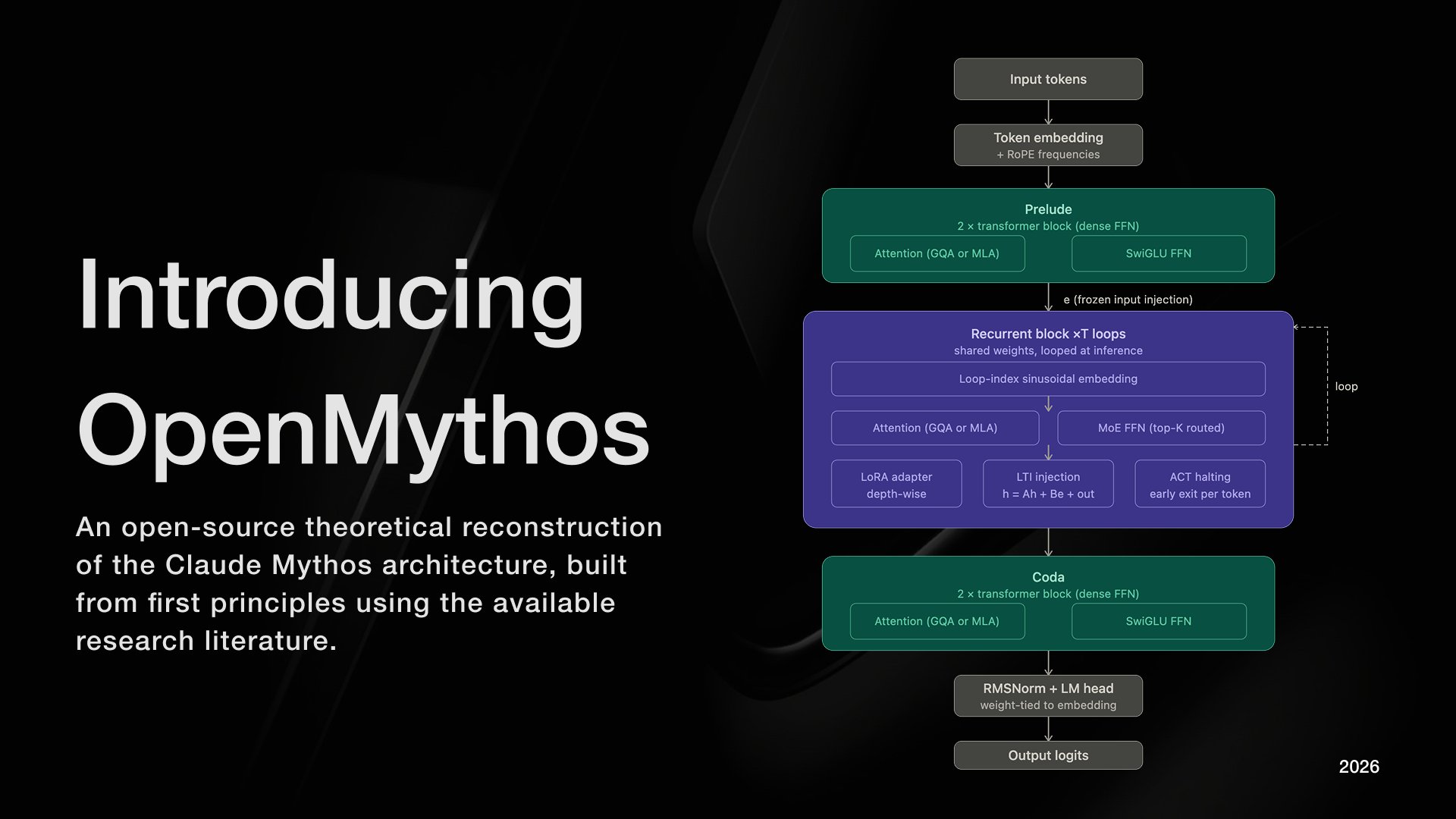
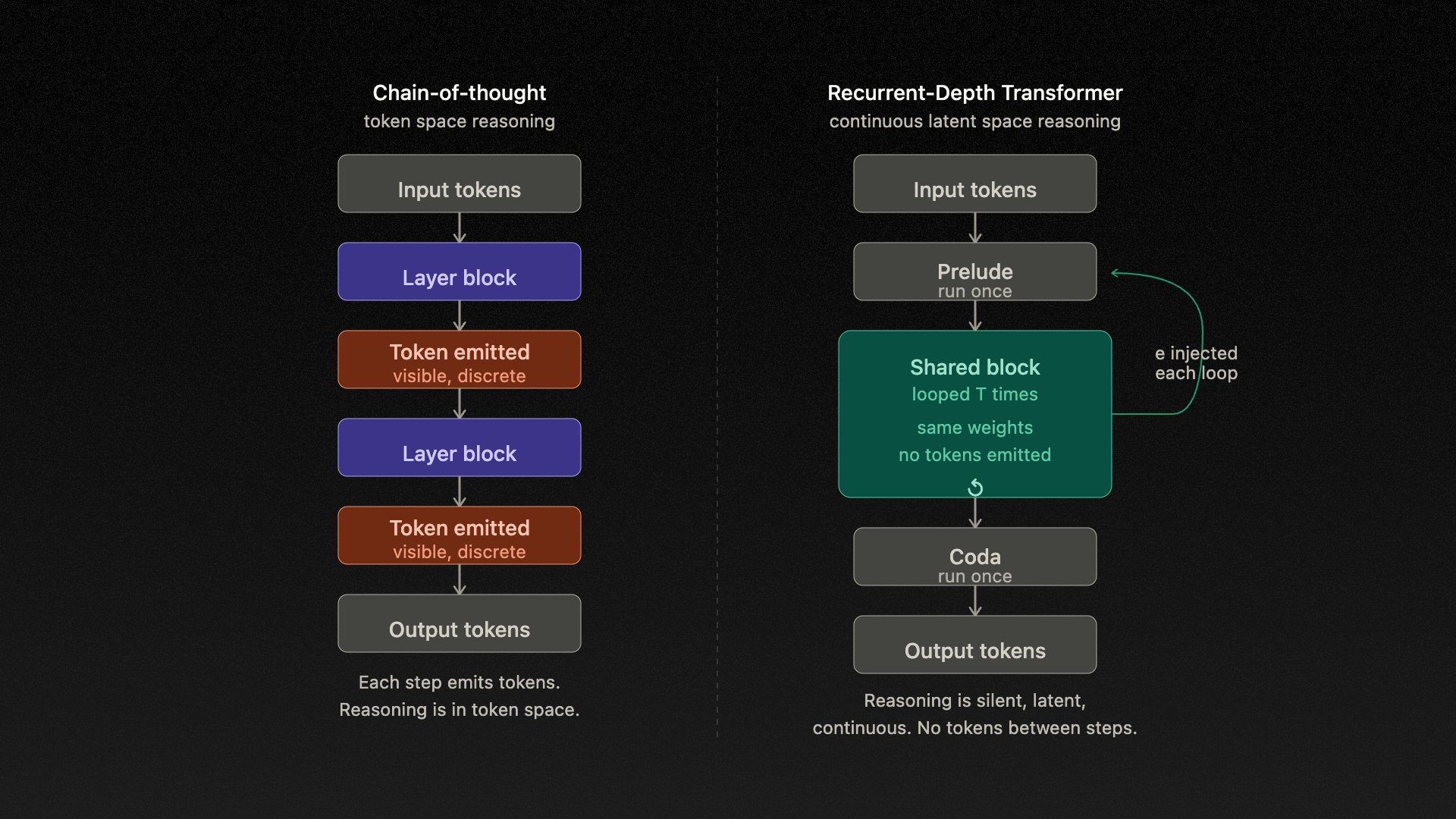
I hypothesize that Mythos is a Recurrent-Depth Transformer (RDT) a class of looped transformer in which a fixed set of weights is applied iteratively across T loop steps within a single forward pass.
Crucially, reasoning occurs entirely in continuous latent space. There is no intermediate token emission between steps. This is structurally distinct from chain-of-thought and has been formally analyzed (Saunshi et al., 2025; COCONUT, 2024).
3 / 7
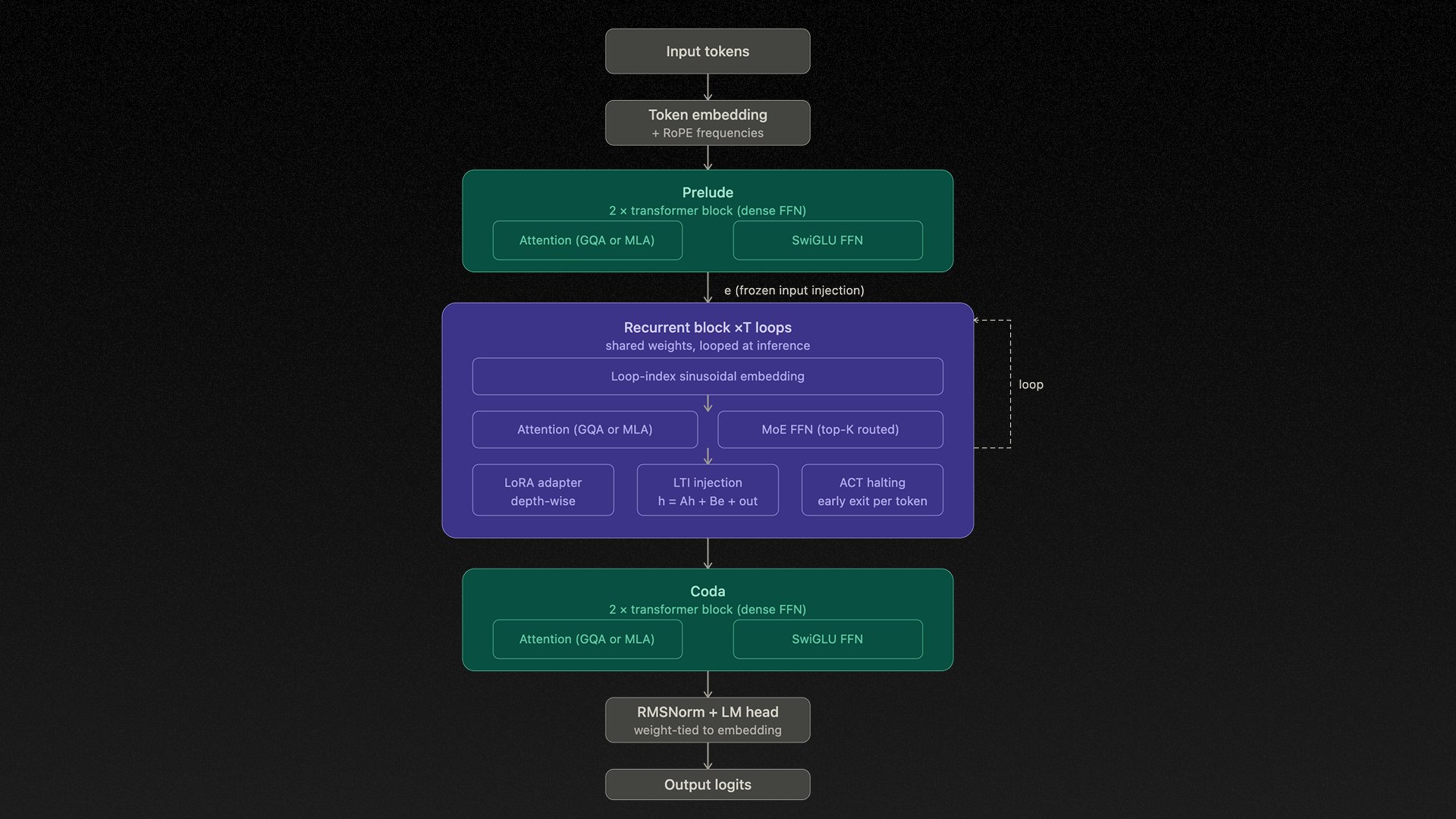
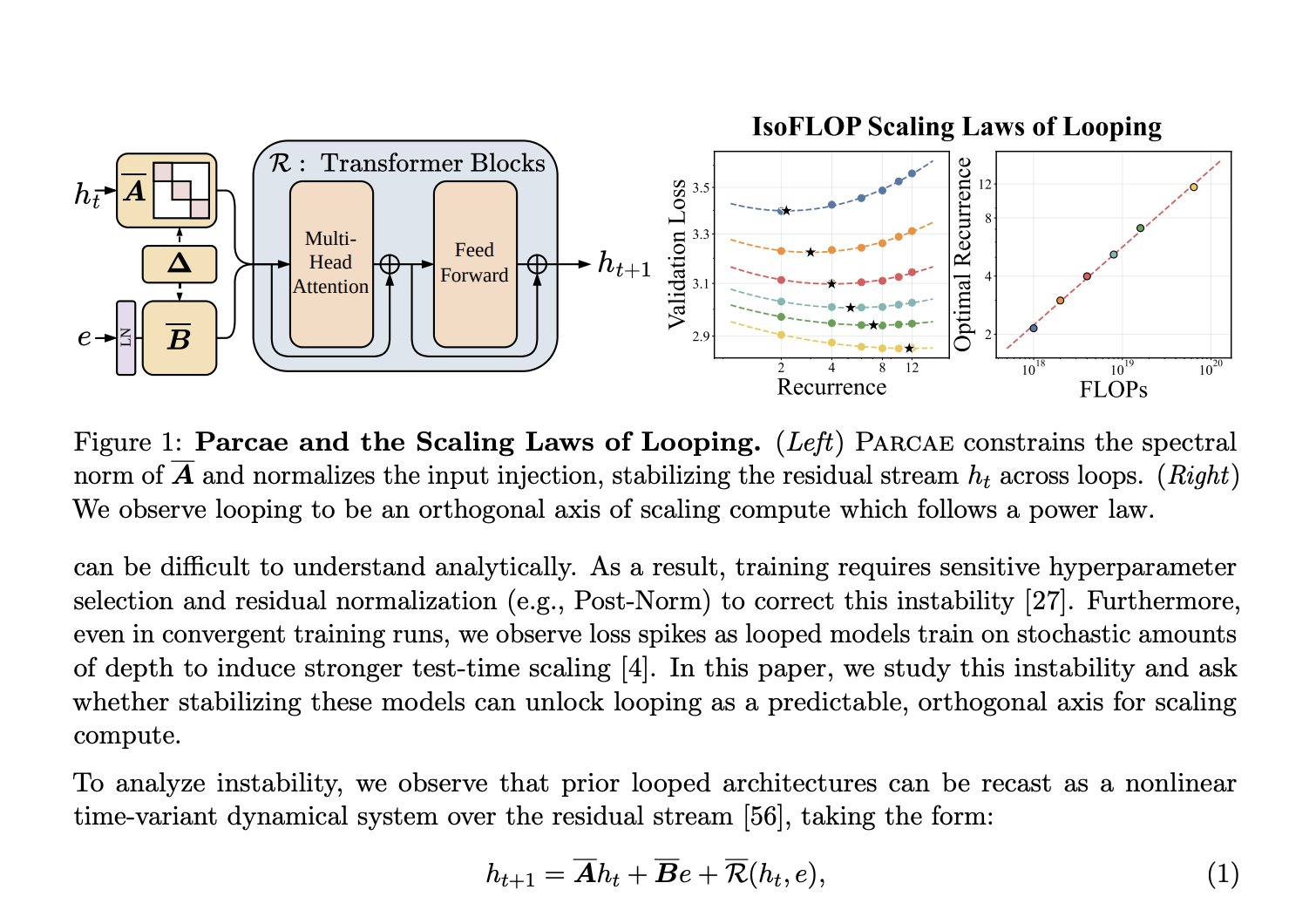
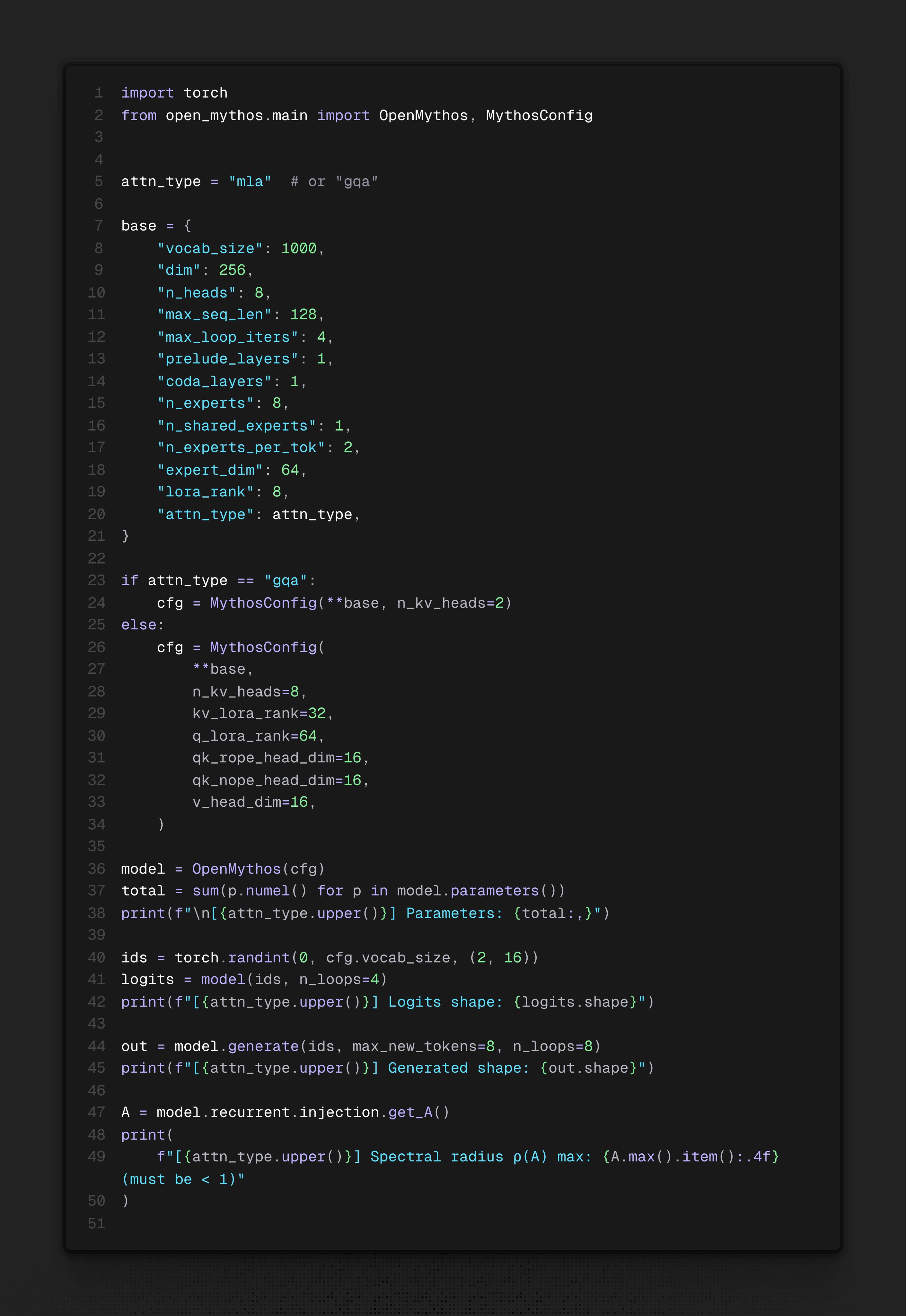
The recurrent block executes one shared TransformerBlock for up to T=16 loop iterations. At each step, the frozen encoded input e is re-injected via a stable LTI update rule: h_{t+1} = A·h_t + B·e + Transformer(h_t, e)
The FFN inside this block is a Mixture-of-Experts layer, following DeepSeekMoE's design a large pool of fine-grained routed experts, with only a sparse top-K subset activated per token, alongside a small set of always-active shared experts that absorb common cross-domain patterns.
Critically, the router is selecting distinct expert subsets at each loop depth meaning every iteration is not merely a repetition, but a computationally distinct pass. MoE provides domain breadth; looping provides reasoning depth.
4 /
The full architecture is:
Prelude → Recurrent Block → Coda
Prelude and Coda are standard transformer layers run once. The Recurrent Block is the computational core. Attention defaults to Multi-Latent Attention (DeepSeek-V2) caching a compressed low-rank KV latent rather than full K/V tensors, yielding a 10–20× reduction in KV memory at production scale.
Three further mechanisms stabilize the loop:
LTI-constrained injection (ρ(A) < 1 by construction),
Adaptive Computation Time halting per position,
Depth-Wise LoRA adapters for per-iteration expressiveness.
5 /
On parameter efficiency: a looped model with k layers run L times achieves the quality of a kL-layer standard transformer with only k layers of parameters.
Empirically (Parcae, Prairie et al., 2026): at 770M parameters, an RDT matches a 1.3B standard model on the same training data. Reasoning depth is a function of inference-time compute, not stored parameter count.
This reframes the scaling debate. The relevant axis is loop depth at inference, not model size at training.
6 /
OpenMythos contributes:
A fully open, configurable PyTorch implementation of the RDT hypothesis with MoE FFN and Multi-Latent Attention
LTI-stable recurrent injection (Parcae) integrated as a first-class training primitive
Depth-wise LoRA adapters enabling per-iteration behavioral differentiation without additional parameter overhead
A reproducible research baseline for studying looped transformer dynamics, scaling behavior, and inference-time reasoning depth
Github: github.com/kyegomez/OpenMythos
7 /
This is an open research effort. We welcome contributions on training stability, scaling experiments, loop depth analysis, and alternative attention mechanisms.
If you work on recurrent transformers, MoE, or inference-time scaling we would value your involvement.
Repo → github.com/kyegomez/OpenMythos
Discord → discord.gg/EamjgSaEQf
8 /
References
Many thanks to @realsigridjin @yuekun_yao @hayden_prairie for their work.
Papers
Fine-grained expert segmentation and shared expert isolation in MoE: arxiv.org/abs/2401.06066
Loop, Think, & Generalize — Implicit Reasoning in Recurrent Depth Transformers: arxiv.org/pdf/2604.07822
Parcae — Scaling Laws for Stable Looped Language Models: arxiv.org/abs/2604.12946
Parcae blog: sandyresearch.github.io/parca…
Universal Transformers: arxiv.org/pdf/1807.03819
Reasoning with Latent Thoughts — On the Power of Looped Transformers: arxiv.org/abs/2502.17416
Training Large Language Models to Reason in a Continuous Latent Space: arxiv.org/abs/2412.06769
Relaxed Recursive Transformers — Effective Parameter Sharing with Layer-wise LoRA: arxiv.org/pdf/2410.20672
this paper drops a big hint about why claude mythos so good
theory: it's a looped transformer (lt). instead of stacking more layers, you loop the same layers multiple times
the authors tested two hard problems that break normal transformers.
systematic generalization → can the model combine facts it never saw combined during training?
depth extrapolation → can it reason deeper than anything in training data?
vanilla transformers fail both but looped transformers pass both
the systematic generalization result is wild, training goes through 3 distinct phases, then suddenly groks it, ood performance jumps off a cliff upward
depth extrapolation is even wilder, train on 20-hop reasoning, test on 30-hop, it just works. the trick is adding more loop iterations at inference
so more loops = deeper reasoning chains
no chain of thought needed. this is all happening inside one forward pass
current llms already memorize tons of facts during pretraining
the bottleneck is composition, they can't chain what they know to answer novel questions
loops seem to unlock that composition for free
if mythos is actually running this architecture, it explains the vibes, same weights, more thinking, better answers on hard stuff
expect everyone to start pretraining looped models next
9 /
Again, this is theoretical. Take this with a grain of salt.
@threadreaderapp unroll